SYNDATA
SYNDATA. Corpus collection of marked syntactic constructions
SYNDATA (“syntactic data”) is a corpus collection of marked syntactic constructions in Italian, French, Spanish, English and German. Most of these structures have been extracted from the CONTRAST-IT and COMPARE-IT corpora in the frame of the ICOCP research project (2011-2015).
The SYNDATA corpus collection comprises marked syntactic constructions belonging to the group of cleft constructions. Here are some representative corpus examples of these constructions:
- sarà l'aria decisamente più fresca a caratterizzare i prossimi giorni (Italian frase scissa)
- A dirlo è Luca Mercalli (Italian frase scissa inversa)
- chi lo ha messo lì è il presidente della Repubblica (Italian frase pseudoscissa)
- ce sont les Marseillais qui vont en faire les frais (French phrase clivée)
- Ce qui compte pour elle, c’est de témoigner(French phrase pseudo-clivée)
- Es una decisión difícil la que han tenido que tomar (Spanish oración hendida)
- it was that attitude that got me in the position I'm in (English cleft sentence)
- Aber es waren nicht die Gebäude, die auffielen, es waren die Berliner (German Spaltsatz)
In the SYNDATA corpus collection, each example is given with a minimal context, ranging from 1-3 sentences before and/or after the marked syntactic construction. For copyright reasons, we are not able to provide more context for each occurrence. However, most of these example can easily be found on the internet or in the CONTRAST-IT or COMPARE-IT corpora.
Composition of the SYNDATA corpus collection
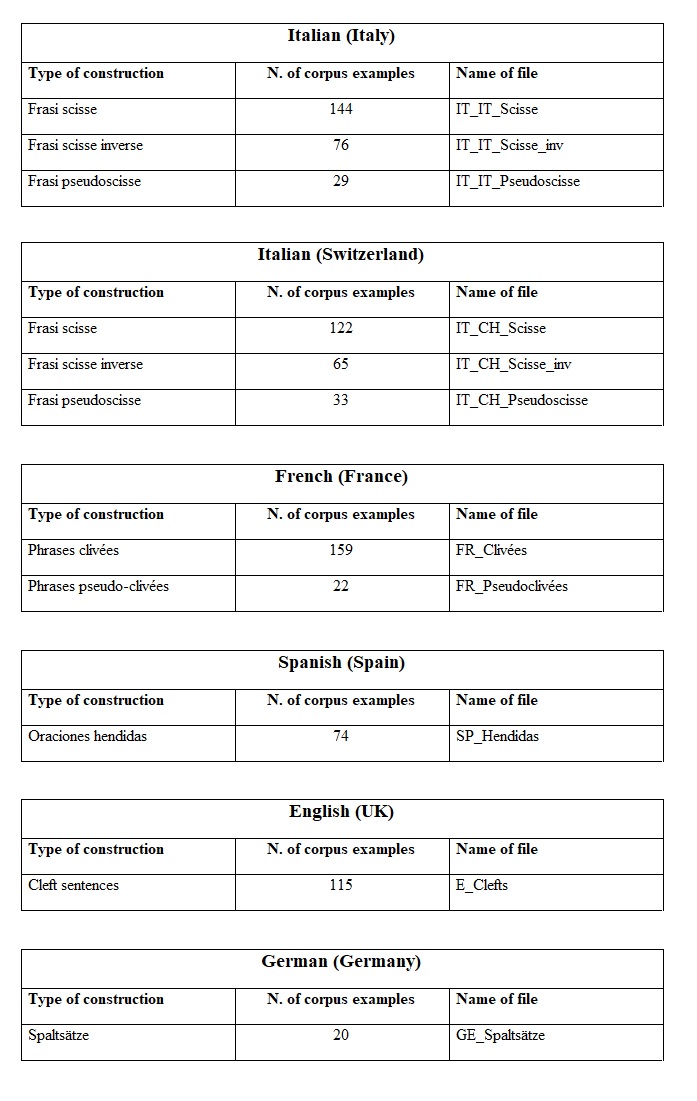
The following tables specify the number of corpus examples collected for each language (we also distinguish Italian written in Italy and in Switzerland). In the third column to the right, you find the name of each file (this is important information if you want to receive the files; for more information on this issue, see “How to get the files” below).
In the future, we plan to code each corpus example for a series of grammatical and informational properties and release a database with new data and a new interface. For the beta version of the first release, we would be grateful for any suggestions on improving the data and on the features that would be useful to code in the search interface of the database.
How to get the files
The SYNDATA corpus collection includes a series of files (in the form of word documents) listing separately specific marked syntactic constructions in a given language. To receive one or more file(s), please email anna-maria.decesare@clutterunibas.ch with the following information:
- your name and email address
- institutional affiliation (if applicable)
- the name of the file(s) you want to receive
- a short explanation describing your interest in the data and how you will use it (research, teaching etc.).
This information is intended to give us an idea of how the data is used and how to further develop and improve it in the future.
Acknowledgments and how to quote SYNDATA
The data included in the SYNDATA corpus collection has been gathered by the following SNSF-collaborators:
- M.A. Federico Aboaf (Italian from Italy; German)
- Dr. des. Rocío Agar Marco (German, Spanish)
- Dr. Laura Baranzini (Italian from Italy, French)
- Prof. Dr. Anna-Maria De Cesare (Italian from Italy and Switzerland; French)
- Dr. Davide Garassino (Italian from Italy and Switzerland; English)
If you use SYNDATA in your research, please acknowledge it by referring to:
De Cesare, Anna-Maria (2011-2018), Contrast-it. SYNDATA. University of Basel. <link en syndata>https://contrast-it.philhist.unibas.ch/en/syndata/