CONTRAST-IT. Corpus
CONTRAST-IT. A multilingual comparable corpus
CONTRAST-IT is a medium-size multilingual corpus created on the basis of a comparable collection of articles published electronically in online daily newspapers. The CONTRAST-IT corpus is based on a text collection totalling ca. 1.5 million words. The articles are written in five languages: Italian (from Italy: IT), French (from France: FR), Spanish (from Spain: SP), English (from the UK: E), and German (from Germany: G). Each corpus is comparable in size. The size of each language subcorpus is given in Table 1.

The websites serving as sources for the data collection on which the CONTRAST-IT corpus is based include some of the most visited and popular online national newspapers. The articles belong to different thematic sections (politics, economy, sports, etc.). Click here to see a detailed description of the CONTRAST-IT corpus.
CONTRAST-IT SELECT. A specialized multilingual comparable corpus
In light of the central role played by language comparability in contrastive and comparative linguistics, the CONTRAST-IT SELECT corpus has been devised based on the same data collection used in the creation of the CONTRAST-IT general corpus.
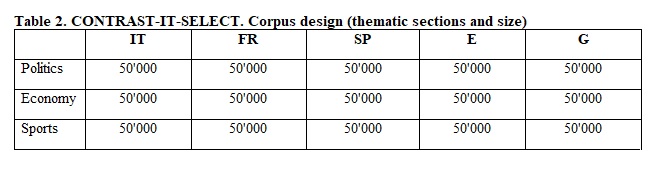
The CONTRAST-IT SELECT corpus is made of highly comparable language subcorpora: each of them includes the three same thematic sections (politics, economy and sports) and each thematic section has the same size (50’000 words). The corpus design is presented in Table 2.
Click here to see a detailed description of the CONTRAST-IT SELECT corpus.