COMPARE-IT. Corpus
COMPARE-IT. A monolingual comparable corpus
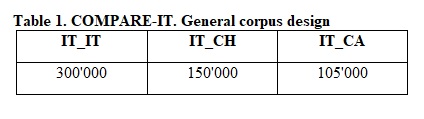
COMPARE-IT is a small-size monolingual corpus created on the basis of a comparable collection of articles published electronically in online daily newspapers written in Italian. The COMPARE-IT corpus is based on a text collection totalling over 550,000 words. The text collection includes articles written in Italy (IT_IT), Switzerland (IT_CH) and Canada (IT_CA). The general corpus design of COMPARE-IT in presented in Table 1.
Click here to see a detailed description of the COMPARE-IT corpus.
COMPARE-IT SELECT. A specialized monolingual comparable corpus
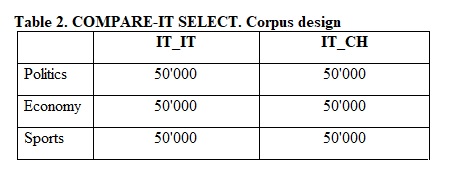
In light of the central role played by language comparability in contrastive and comparative linguistics, the COMPARE-IT SELECT corpus has been devised based on the same data collection used for the COMPARE-IT general corpus (see Table 1).
The COMPARE-IT-SELECT corpus is made of highly comparable language subcorpora: each of them includes three same thematic sections (Politics, Economy and Sports) and each thematic section has the same size (50,000 words). The corpus design is presented in Table 2. At the moment, COMPARE-IT SELECT only allows comparing Italian written in Italy and in Switzerland. In the future, we would like to add new data on journalistic Italian written in Canada, Croatia, Argentina etc.
Click here to see a detailed description of the COMPARE-IT SELECT corpus.